VMware Purple Screen of Death troubleshooting for random crashes with disk errors in the homelab.
Hi everyone,
Time for a new blog post about the adventure I’ve been having for the past two days.
On June 2nd, my server, a DL380G6 started to suddenly take-off. The fans were roaring at 70%, and the temperature sensor near the PCI Riser was showing 110 C. Of course this is not supposed to happen, in this blog post, I will take you through my experience of troubleshooting this and hopefully this can help you.
Okay, so we know that the temperature sensor is showing a very high temperature. Let’s remove the PCI riser and see if the sensor is defective or not. I removed it, and it was showing a normal 60 C. Okay, so there is some PCI card that is getting very hot.
Step two: we put the riser back in. However, since my has two cards in it, I leave one out. I left the Smart Array P420 RAID controller in, and took the quad gigabit NIC out. I turn it back on, and once the sensor initializes, I check it. It was once again showing 110 C. Very odd.
Next I swap the cards around, having the NIC in the bottom slot, and I take out the RAID controller. I once again turn it back on, and now it seems to be fine. Temperature shows 64 C. Well, it seems to be the controller then.
Next step: let’s put the RAID controller back in, and leave its backup capacitor disconnected. I saw that in the IML that the controller says that it is defective. Maybe this causes it. I disconnect the backup capacitor, and now all seems okay. So maybe it was the backup capacitor.
I put the network card back in, start the server once again and all seems well. I boot the ESXi host and let VMs slowly start back up. However, we’re not done yet!
VMware suddenly gives a purple screen of death, as you can see in this screenshot:
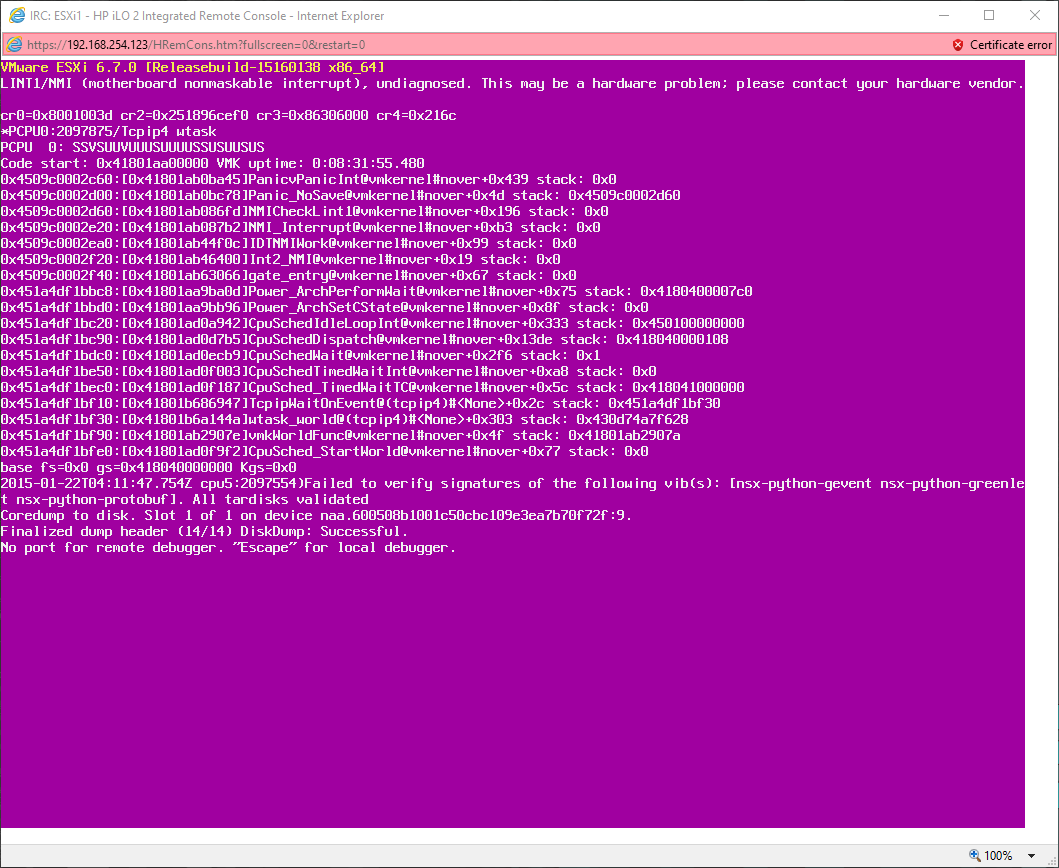
I thought it was a one-time thing. (in a production environment, you should not do this! Immediately investigate why the crash occurred!). I restart the server and try agan. This time, it crashes, once again. When I look at the logs through the debugger, I see that nothing really is showing, other than slow response times.
I shut the server back down and take out the controller. The heatsink feels quite warm. I press on it a little bit to make sure that it’s still secured in place, and check the SAS connectors to make sure that they are seated in properly with no dust in them. I turn the server back on, however, now it’s taking off again. Showing 113 C on the sensor.
By accident while taking out the riser card, I touch the heatsink of my RAID controller and burn my hand. So the problem is definitely not fixed yet, and properly the controller crashed because of overheating.
I removed the controller and put the SAS cables in the on-board P410i controller. Temperatures are normal and the server has been running for a bit over a day without crashing.
Ultimately, it looks like my P420 controller has died. I should still have warranty on it from the company I bought it from, so I’m going to try to RMA it. Hopefully that will be possible.
Thank you for reading, if you have any questions feel free to contact me on my website or Twitter and I hope you learned something.
Have a great day